al-Makhzan: An AI-Powered Digital Library for Islamic Scholarship
The Opportunity
The Shia scholarly tradition spans over a thousand years of intellectual output in Arabic, Persian, Urdu, Gujarati, English, and other languages. Yet there is no single platform where a researcher can search across this corpus. Existing digital libraries serve fragments: Shamela covers Sunni Arabic texts, al-Islam.org offers English translations, and while Noorlib hosts a comprehensive Persian and Arabic collection, it remains difficult to access and is based in Iran. A Hawza scholar or university academic researching a topic in fiqh, kalam, or history must navigate four or five platforms in different languages, manually cross-referencing results — a process that can take days for work that should take minutes.
AI is now capable of transforming this. An AI-powered research tool can search across tens of thousands of texts simultaneously, identify relevant passages across languages, and surface conceptual connections that no keyword search would find. A scholar asking about the concept of wilaya could instantly discover relevant discussions in Arabic hadith collections, Persian philosophical commentaries, and English academic works — all from a single query. These capabilities exist today but have not yet been applied to Islamic scholarship.
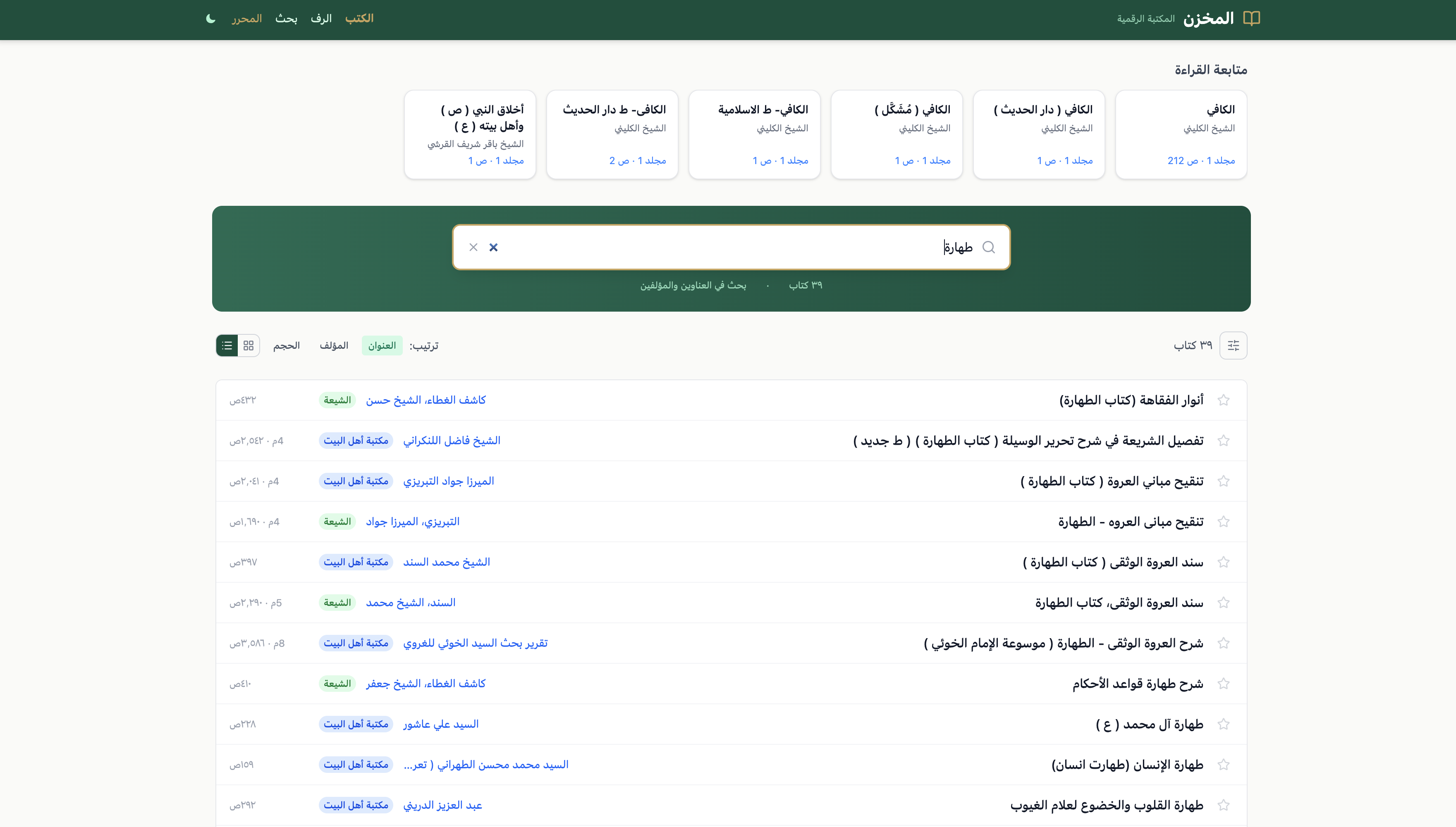
al-Makhzan (المخزن — "the repository") is that tool: a comprehensive, AI-powered digital library and research platform centred on the Shia scholarly tradition, with multilingual support from classical Arabic and Persian through to English, Urdu, and Gujarati. A working prototype already exists with 14,075 books and 11.35 million pages of searchable full text. We propose to expand it into a full research platform serving the Hawza, academia, and researchers worldwide — integrating the World Federation's own publications alongside tens of thousands of classical and contemporary texts, and deploying AI capabilities that will make this the most advanced Islamic digital library in existence.
What Makes al-Makhzan Different
Current State
The platform is built and functional. The existing corpus includes:
| Source | Books | School | Content | Status |
|---|---|---|---|---|
| lib.eshia.ir | 7,534 | Shia | Full text, Arabic/Persian | Integrated |
| Ahlulbayt Library | 13,903 | Shia | Full text + table of contents | Integrated |
| TOTAL | 14,075 unique works | 11.35 million pages | Searchable now |
Additional sources catalogued and ready for integration:
| Source | Books | School | Content | Integration effort |
|---|---|---|---|---|
| World Federation publications | ~700 | Shia | English PDFs | OCR + import |
| Ansariyan Publications | ~100 | Shia | English/Arabic PDFs | OCR + import |
| al-Islam.org | ~1,200 | Shia | English text (HTML) | Web scraping + import |
| Shamela (المكتبة الشاملة) | ~8,000 | Sunni | Full text (classical corpus) | File extraction + import |
| Alfeker.net | 5,470 | Shia | Scanned Arabic PDFs | OCR (long-running) |
| Mktba.net | 9,124 | Shia | Scanned Arabic PDFs | OCR (long-running) |
| IslamicLibrary.com (Urdu + Gujarati) | ~4,700 | Shia | Scanned PDFs, Urdu/Gujarati | OCR (Phase 3) |
| Waqfeya (المكتبة الوقفية)* | 11,747 | Sunni | Scanned PDFs on Archive.org | OCR (optional Phase 4) |
| TOTAL | ~41,200+ books |
Including the existing 14,075 works, the combined corpus will contain over 55,000 books — an estimated 35,000–40,000 unique works after deduplication of overlapping editions across sources.
*Waqfeya digitisation is optional and subject to additional funding (see Phase 4).
Development Roadmap
- Deploy al-Makhzan to production hosting with a dedicated domain
- Import and digitise the World Federation's ~700 publications
- Import Ansariyan Publications (~100 books)
- Integrate al-Islam.org's digital library (text-based, no OCR required)
- Import Shamela's ~8,000 texts (predominantly Sunni — transforms the library into a cross-tradition resource)
- Run deduplication across all integrated sources
- Provide access to an initial cohort of selected researchers worldwide
- Deploy dedicated digitisation server (Mac Studio) for continuous 24/7 OCR processing
- Begin OCR conversion of Alfeker.net (5,470 books) and Mktba.net (9,124 books) — estimated 9+ million pages of scanned Arabic text
- Build a normalised authors database (canonical names, death years, biographical data)
- Deploy AI capabilities: Arabic morphological search, automated metadata enrichment, OCR quality correction using locally-hosted AI models
- Complete OCR conversion of Alfeker and Mktba collections
- Implement semantic search (find conceptually related passages across the entire corpus)
- AI Research Assistant with source citations
- Cross-language retrieval (Arabic query finds relevant Persian and English results)
- Investigate and integrate additional text-based sources (Turath.io and others)
- Mobile app aimed at a general audience, focused on Shia texts and English-language works
- Multilingual expansion: OCR and import of ~4,700 Urdu and Gujarati books from IslamicLibrary.com
- Plan phased rollout beyond initial researcher cohort
Digitise the Waqfeya collection — 11,747 Sunni scholarly works (~26,000 volumes, ~8 million pages). Estimated additional cost: ~$35,000.
Budget
| Item | Cost |
|---|---|
| Infrastructure | |
| Dedicated digitisation and AI development platform (Mac Studio M4 Max, 64GB RAM)* | $3,550 |
| Cloud hosting — Year 1 (DigitalOcean VPS, 16GB RAM, 320GB SSD, backups) | $1,150 |
| Domain registration (al-makhzan.org) and DNS | $16 |
| Digitisation | |
| OCR processing of World Federation + Ansariyan publications (~800 books — digitisation, text extraction, AI-assisted processing) | $1,500 |
| OCR processing of Alfeker + Mktba collections (~9M pages — AI-assisted OCR, pre/post-processing) | $35,000 |
| OCR processing of IslamicLibrary.com Urdu + Gujarati collection (~4,700 books, ~1.5M pages) | $6,000 |
| AI and Development Tools | |
| AI-assisted development and maintenance platform (Claude Code, annual) | $2,400 |
| Search embedding and AI API costs | $500 |
| Mobile App | |
| Development of prototype iOS and Android app with Gentech | $5,000 |
| TOTAL | $55,116 |
Ongoing annual costs after Year 1: approximately $3,550 (hosting, AI tools, API usage). Digitisation costs are a one-time investment in creating a permanent digital asset.
*Purchased in GBP (£2,799) at current exchange rates.
Team
- Alex Khaleeli Project lead, platform architecture, data pipeline development, AI integration
- Haider al-Rekabi Full-stack developer, frontend/backend development, ongoing maintenance
Access Model
The digital library will initially serve Shia researchers, the Hawza (Islamic seminary) community, and academics worldwide via authenticated access. Following an evaluation period, a phased rollout to broader audiences will be planned, culminating in a mobile app aimed at the general community.
About the Platform
al-Makhzan is built on modern, maintainable technology: a Python backend with full-text search optimised for Arabic script, a React web frontend designed for right-to-left text, and a SQLite database engine capable of handling tens of millions of pages. The dedicated Mac Studio serves dual purpose as a 24/7 digitisation server (running continuous OCR processing) and an AI development platform (hosting local language models for search and text processing). All infrastructure is designed to be operated and maintained by a small team.